PostgreSQL中varchar类型like前置%查询命中索引的方法
条评论上一篇中,我们学习了PostgreSQL中想要让varchar类型支持like查询能够命中索引,需要注意的地方。但是即便是创建索引时,指定了操作符类varchar_pattern_ops,在使用like查询的时候,还是只能保证sometext%这种查询能够命中索引,但是%sometext这种是无能为力的,见下图。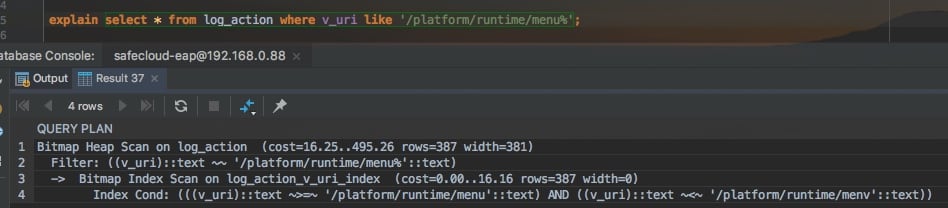
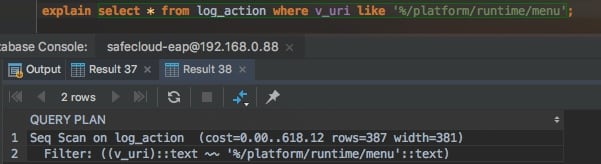
所以如果需要支持%sometext方式的索引查询,还需要再做点工作:
create extension pg_trgm;CREATE INDEX log_action_v_uri_index ON log_action using gist (v_uri gist_trgm_ops);CREATE INDEX table_name_md5_index ON table_name using gin (md5 gin_trgm_ops);1. 上面`gist`索引时有损的,后来研究支持,发现`gin`更合适,速度更快 **强烈推荐**
CREATE INDEX table_name_md5_index_btree ON table_name (md5 text_pattern_ops);
然后重新执行`explain`,就能看到命中索引了

关于`btree`索引与`gist`索引的应用场景,我们以后再探讨。 现在我们先看看同样支持`sometext%`查询命中索引的情况下,我们该用哪种呢。
1. 首先是查询速度,这次我们换百万行的数据来测试
* 先看`btree`的
* 再看`gist`的
* 直观来看,采用`gist`索引规划期给的时间是更快的。但是如果采用`explain analyse`尝试获取真实结果的话,答案就恰恰相反了
* 先看`btree`
* 再看`gist`
* 结果匪夷所思,在`gist`索引的情况下,不论怎么测试,最终的`Execution time`都保持在500ms以上。而`btree`实际执行时间才1ms多。我尝试重启数据库,来保证数据没有缓存,但是`btree`反馈的实际执行时间也不过就11ms多,之后又会下降了1ms量级。这其中的原因,是因为`gist`是一种有损索引,所以不能像`btree`索引那样,直接把值取出来。
* **结论:通常情况下btree的查询速度会远好于gist,但是如果gist索引列只参与条件判断,不参与select,gist的速度还是比较理想的**
2. 然是是创建索引的速度
* 先看`btree`
* 再看`gist`
* **结论:创建索引的速度,btree远好于gist**
3. 还有功能上**gist索引不支持=查询,也就是如果除了模糊匹配,还需要精确匹配的话,必须引入btree索引**
### 总结
* `varchar`类型,如果需要模糊查询,需要这么来create extension pg_trgm; CREATE INDEX table_name_md5_index ON table_name using gin (md5 gin_trgm_ops);但是此方案只支持`左锚定`
* 如果需要不局限于`左锚定`的模糊查询,还需要这么来
- 如果还需要精确等值查询,请务必保留
btree索引
本文标题:PostgreSQL中varchar类型like前置%查询命中索引的方法
文章作者:牧云踏歌
发布时间:2018-08-02
最后更新:2018-08-03
原始链接:http://www.kankanzhijian.com/2018/08/02/PostgreSQL_select_varchar_like_front_/
版权声明:本博客文章均系本人原创,转载请注名出处